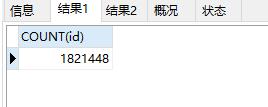
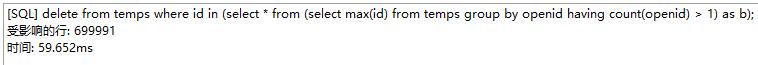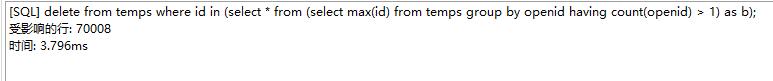先说一下需求,最近做获取微信用户openid的时候 由于Chrome拉数据的时候出了问题,100万的数据 重复了80多万。那么这里需要把openid去重
附录:查询表数量相关
SELECT COUNT(age) FROM tableA
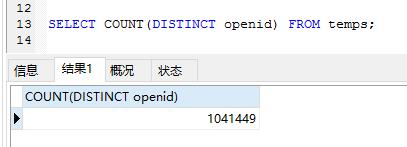
SELECT COUNT(DISTINCT age) from tableA
1.网上的一种说法,我试了一半不试了,太™慢了这里贴出来
先对要去重的表进行索引(处理重复的那个字段).将数据group by后导入到新的表中,导入时,可能需要分多次导入,因为电脑的内存有限,设置一下tmp_table_size或许可以一下子多导点
使用sql如下: Insert into Table2 select * from Table1 group by 重复字段名称 limit 100000
使用以上SQL,并个性Limit参数多进行几次导入操作即可
Insert into m_temp select * from temps group by openid limit 440000,10000;
2.这个方法亲测可以用 delete from 表名 where 字段ID in (select * from (select max(字段ID) from 表名 group by 重复的字段 having count(重复的字段) > 1) as b);
delete from temps where id in (select * from (select max(id) from temps group by openid having count(openid) > 1) as b);
我用的是navicat处理,执行了几次才完成