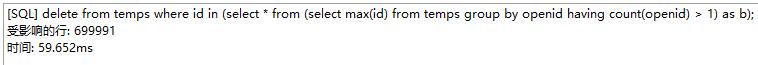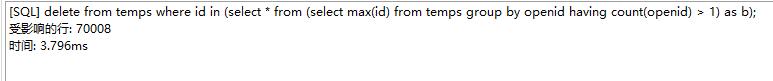方法1
import datetime
starttime = datetime.datetime.now()
#long running
endtime = datetime.datetime.now()
print (endtime – starttime).seconds
方法 2
start = time.time()
run_fun()
end = time.time()
print end-start
方法3
start = time.clock()
run_fun()
end = time.clock()
print end-start
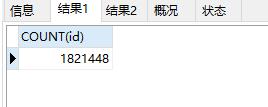
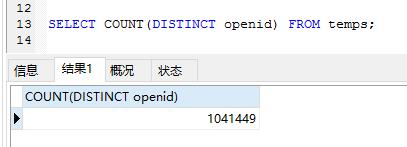
方法1和方法2都包含了其他程序使用CPU的时间,是程序开始到程序结束的运行时间。
方法3算只计算了程序运行的CPU时间
来源:http://blog.sina.com.cn/s/blog_56d8ea900100xzg3.html